Grokking Streaming Systems Reading Notes
本文是 Grokking Streaming Systems Reading Notes,书中对应的code,帮助快速了解流系统中的各种概念。
Key Characteristics
理解流系统,需要回答为什么需要它,第一个问题:没有 streaming system 的时候,会选择什么技术解决实时计算问题?而这些技术遇到什么问题,从而衍生出了流系统?
书中举例:一个大桥的 过路收费站,需要实时准确统计 通过车辆的个数(需要根据汽车种类分组)。
1.首先很自然想到的是,设计 backend services,接受 sensors 的 http 请求,再进行计数存储,返回 sensors response。
存在问题:holiday traffic 增加时候,整个系统的 latency 很高,导致 inaccurate 实时数据。
2.改进方式:缩短通信链路,即 sensor 只负责发送 request,不再等待 response,而实时数据地获取,是 loop pull system 出来的。
这种方式,从 high level 来说很类似 streaming systems,是一个 异步模型。
因此,书中会介绍,从0开始设计一个流系统,通过一个通用的方案,来满足production级别的实时计算需求,以解决上面提到的 latency 问题。
介绍流系统概念之前,总结一下 后端服务/批处理/流处理 的特点:
- Backend services: request/response 同步模型, main loop + multi-threading 直接与 client 交互
- Batch processing systems:
- execute tasks at scheduled times
- process huge amounts of data efficiently
- stage by stage processing
- Stream processing systems:
- 解决 batch processing 的 latency,实现
low-latency - data events are processed
as soon as possibleonce they are received - process huge amounts of data with low latency
- 与批处理架构类似,whole process 由多个 components 构成,主要区别:components are
long running processes
- 解决 batch processing 的 latency,实现
batch 和 stream 都是由 multi-stage architecture 构成,它的特点:
- flexible:灵活添加删除 stage
- maintainable:一个复杂的流程,通过灵活组合多个 stage 实现,分治实现
- scalable:stage 可以横向扩展增大 throughput
流系统中的5个核心概念:
- event:一个事件,通常为 Tuple、Element、Message,代表一个条不可分割的事件
- stream:ongoing delivery of events + 两个 components 之间的 connection
- source:将 outside data 接入流系统的 entry point
- operator:流系统中 接收和处理 event 的地方,也称作 transform
- job:也叫 pipeline。通常由多个组件组成(sources、operators), 通过 stream 连接这些 components
参考示例代码ch02核心部分,帮助理解概念:
- API:
- Component:流系统的基础类,包含一个
OutgoingStream代表输出的流,因此,source和operator都会继承于它,以实现串联 - Stream:代表 Component 的输出流,它包含一系列
Operators,用于后续处理
- Component:流系统的基础类,包含一个
- Engine:
- InstanceExecutor:包含
incomingQueue和outgoingQueue,用于接收和发送数据,比如 Source/Operator InstanceExecutor - ComponentExecutor:包裹 Component 和 InstanceExecutor,会 loop pull event 然后进行处理,比如 Source/Operator Executor
- EventDispatcher:用于 connect executors,并分发 event 到具体的 executor
- InstanceExecutor:包含
大致流程如下图所示:

Parallelization
继续上面大桥收费站示例,处理大量 traffic 时,通过增加收费站个数,来增加 throughput。这也是常见增加系统吞吐的方式,paralleization,即增加 operator instances 的数量,来同时并行处理多条数据。
带来了新问题,对一个 event 来说,它该发往哪个 operator instance 呢?
因为,并行扩展的 operator 之间是互相独立的,即使从时间线上 eventA 在 eventB 之前发生,但当它们分发到不用的 operator instance 上后,不能保证 eventA 一定会在 eventB 之前处理完成。这个情况,在单 operator instance 情况下不会发生,因为 event 会保持先后顺序存储在 queue 中。
因此,引入 event dispatcher 用来分发 event,event grouping 来决定 event 发往哪个 instance,从而逻辑上保证 同一组的 event 在一个 Instance 上处理,而避免上面问题。event grouping strategy 可以是:
- Shuffle grouping:event 被伪随机地分发到下游 instance,比如 round-robin 方法轮流分发。
- Fields grouping:通过 event 中指定字段来决定,分发到下游哪个 instance,比如 Hash 取模。
Stream Graph
真实场景下,一个 streaming job 会由很多 operators 组成,这一章会介绍如何 构建真实场景下的 job。
书中示例:一种信用卡欺诈检测系统,它相比于上面的 大桥车辆计数 来说,需要处理 conditional routing 和 errors,即 event 通过不同的计数指标 operator 得出 score ,最终汇总得出一个结果。
也就是说,这个流系统 需要基于 rule-based operators DAG graph job,而不在是一个 straight-line job。
组成 graph 的 stream 需要支持 多入/多出:
- Stream fan-out:一个 Component 包含多个 downstream Components
- Stream fan-in:一个 Component 有多个 upstream Components
如下图是 欺诈检测系统 graph 示意图:

上图中的流引擎有几个问题:
1.fan-out:因为基于现有的设计(源码中ch03 或 上面highlevel main flow图),在 stream fan-out 中,Transaction Source Executor 需要创建3个 outgoing queues,以便让不同 analyzer 能够异步处理自己的 event,每个 queue 都包含相同的 events,当然这也会造成大量的内存开销。
解决方式也很直接,针对不同的 event type,放入对应的 queue 中,即 通过在 executor 的 outgoing queue 之前,加入 channel 层来绑定不同的 outgoing queue,以达到高灵活度。
2.fan-in:上图中的 Score Aggregator,它不同于我们之前的 operator,它需要将多个 streams merge 成一个 stream。
解决方式,将需要 merge stream 的上游 executors,写入到同一个 outgoing queue 中
如下图,展示了 channel 和 merge stream 的过程

Delivery Semantics
分布式系统,比如流系统中,准确性计算,有时会 a little bit more complicated。这一章,通过 delivery semantics 来讨论 流系统中的 accuracy calculation。
我们知道,分布式系统中,failure 时常发生,任何组件都可能出现问题,比如 network、running instance。因此,设计分布式系统时,通常需要保证 reliability,这一点在流系统中也需要考虑。
同时,在流系统中,latency 和 accuracy result 也是经常需要 trade-off 的问题,比如上面 信用卡欺诈检测系统 graph 示意图,average ticket analyzer 所在的机器 hang 住了,没有及时处理 event,下游的 score aggregator 这时要做出取舍。比如,如果保证了 latency,则需要忽略 average ticker analyzer 的结果,直接计算出 inaccuracy 的结果。
介绍 delivery semantics 之前需要补充的概念:
- times processed:一个 event 被 Component 处理的次数
- times delivered:一个 Component 产生 result 的次数,也可认为 event 被成功处理的次数
这两个数看起来,是一个 Component 的输入和输出,大多数情况下它们是相等的,如果出现 failure,则可能 times processed = 1,而 times delivered = 0 的情况。
delivery semantics:也被称作 delivery guarantees 或 delivery assurances。它主要关注的是,流系统 如何保证 delivery(event被成功处理) 在 streaming job 中。
delivery semantics 主要包含3种语义可供选择:
- At-most-once:最多一次,每个 event 被处理不会超过1次,但是
不保证被成功处理 - At-least-once:至少一次,每个 event 被
成功处理 至少一次,但是不保证被处理的次数 - Exactly-once:准确一次,每个 event 仅被成功处理一次,也叫做 effectively-once (有效一次处理,相比描述更加准确,因为考虑容错情况下,event 会被多次处理,但结果和只处理一次是相同的,即幂等的),extremely-hard in distributed systems,参考
不同 delivery semantics 在不同角度下的 tradeoff:
Accuracy:
- At-most-once:No accuracy guarantee because of
missingevents - At-least-once:No accuracy guarantee because of
duplicatedevents - Exactly-once:(Looks like) accurate results are guaranteed
Latency (when errors happen):
- At-most-once:Tolerant to failures; no delay when errors happen
- At-least-once:Sensitive to failures; potential delay when errors happen
- Exactly-once:Sensitive to failures; potential delay when errors happen
Complexity:
- At-most-once:Very simple
- At-least-once:Intermediate (depends on the implementation)
- Exactly-once:Complex
At-most-once
event 没有被 tracked,系统会尽力处理,但如果出现 failure,系统会忽略 errors 继续 running。因此,系统整体的 latency 和 throughput 都没有受到影响,但最终的结果是 inaccuracy。
这也是现实中大多数系统,采用的方式:接受 temporarily inaccuracy 的结果,来换取整个系统的 简单性。
另一个考虑 At-most-once 的优势是,low resource and maintenance cost。
At-least-once
event 会被 tracked,系统中的每个 Component 都要 acknowledge 一个 event 处理成功或失败。因此,流系统会通过一个 acknowledger 来提供一个 tracking mechanism。
acknowledger 会将 event 处理的成功或失败的 message 返给 data source,注意这里的 data source 还是流系统里的 Component,而不是系统之外接入的 source (也就是说 replay event 还在流系统控制中)。
如下图,一个 source component emit 一个 event 后,会先将它 keep 在 buffer 中,等待 acknowledger 的消息,根据处理的成功或失败,再进行 remove event from buffer 或 replay event。

实现 At-least-once 的一些缺点:
- component 需要实现 acknowledge 逻辑 与 acknowledger 交互
events processing order不能保证,比如 [A (failed), B, C, A (successful)] 这种序列也是合法的(可以后续参考 Dataflow 论文)
通常,通过 checkpoint 和 state 共同实现 at-least-once,来满足 fault-tolerant:
- checkpoint:粗浅理解为 系统状态 的一块数据,需要 periodically 保存到一个 storage 中,比如当前处理的 event 在 input log file 中的 offset
- state:通过 checkpoint 可以恢复到系统中某个状态,比如 operator 当前处理的 event 个数
Exactly-once
这个语义需要通过 checkpointing 实现,通过上面的 at-least-once 我们可以用 acknowledger 来实现 event tracking,在出错时进行 replay。
而 exactly-once 的加强点在于,在 source 和 operator 中创建 checkpoints,从而达到 整体系统的 travel back,来实现 rollback。
创建 checkpoint 的方式会通过 source 周期性的发出 checkpoint event 到 downstream components,从而依次传递创建 checkpoint。
以上部分,就是流系统的核心概念,接下来书中第二部分,分别介绍几个流系统中的 advanced topics
- slice stream into meaningful chunks
- join stream data
- stream system recover
- stream state management
Windowed Computations
上面的 信用卡欺诈检测系统中,analyzer 不仅依赖当前的 event,还依赖于一个窗口内的所有 events,共同判断当前消费信息 是否存在欺诈。比如,在1min时间内,一张信用卡在相聚几百公里的地方都有实体店消费记录,这明显是不符合常理的。
在流系统中,通过 windows 能够将看起来无限的 stream 切分为 chunks,再去处理。切分 window 的 strategy 如下
fixed window
固定的窗口大小,包含 time-window 和 count-window,也叫做 tumbling window (翻转窗口)。注意,time-based windows 中一个 window 内的 event count 可能是不相同的,而 event-count-based windows 中一个 window 的 interval time 可能是不同的。
举例,1min内所有 event 会被 group 成一个 chunk 统一处理。但这种计算结果可能不准确。比如,统计重复的 event,但两个 identical event 落在了 2个 fixed window 中,就会被统计2次
sliding window
滑动窗口,类似 fixed-window,它有一个 确定的 slide interval,其中每个 window 都会有 overlap,因此,一个 event 可能属于到多个 window 中。如下图展示的 1min sliding window 和 30s slide interval

滑动窗口 提供了一个机制,可以更加平稳的对事件进行汇总计算,来解决 fixed-windonw 在 信用卡欺诈检测系统 中的 inaccuracy 问题。
session window
key-specific 的 window,代表这个 event key 的 a period of activities,与上面两种 window 不一样,它是以 event key 为维度去分组,同一组里的 window 通过 inactivity gap period 来控制 window 的 open/close。
如下图中,w1 和 w3 之间存在一个 10min 的 inactivity gap

k-v store
上面的3种类型 window 的计算,都会遇到一个问题:在一个 window 中,随着 events 增多,系统所需要的 计算资源 也会越多。也就是说,window size 较小时,则 stream job 计算的会更高效。
然而,现实情况中,流系统需要处理大量 events 的同时,也要保证 latency,因此,events 需要通过外部存储,也需要提供高效的查询。自然想到了,k-v store。参考Flink Using RocksDB。
windowing watermark
首先,需要知道 event 的两个 time:
- event time:event 的创建时间
- processing time:event 被流系统开始处理的时间
正常情况下,一个 event 的 processing time(00:11) 会略大于 event time(00:10),但由于网络延迟等问题,这两个时间的 gap 可能会变大,如果 event time 刚好是 window closed-time,则导致本来应该计算在当前 window 的 event missing 了,同时,这个 missing event 也不能放到下一个 window,因为它的 event time 属于 already-closed window。
比如,event time(00:20),processing time(00:21),但 fixed-window 为 [00:00, 00:20],则这个 event missing 了。
解决方式很简单:keep window open for a litter longer,这个 extra waiting time 就是 windowing watermark。
注意,虽然当前 window 延长一会 closed,但 next window 仍然是 正常时间 open,因此会出现 overlap 的情况,这时 event 会按照 event time 决定放到哪一个 window。
参考Spark Handling Late Data and Watermarking,图不太好画,这里直接贴出spark文档中的示例图:
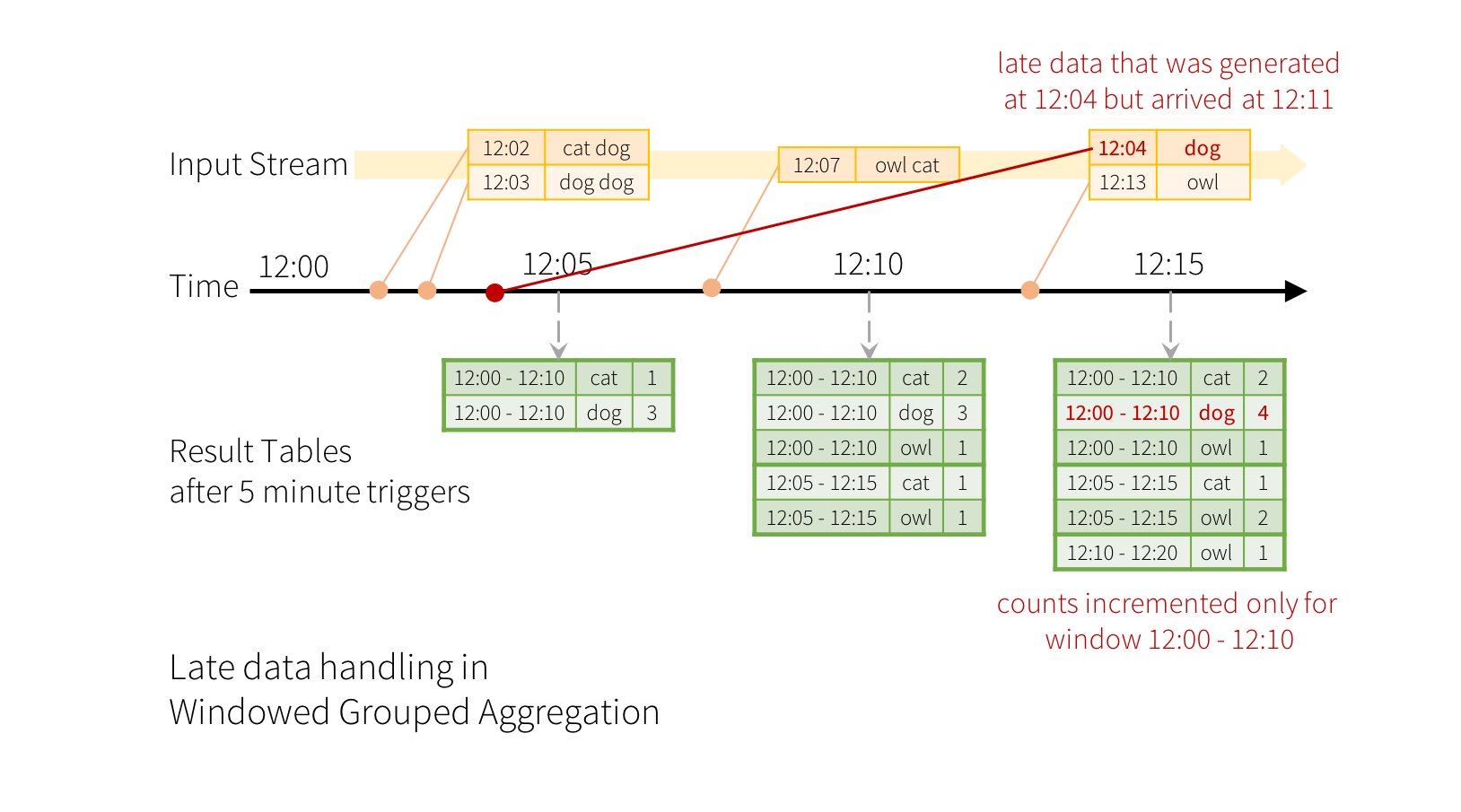
注意:这里的 watermark 是随着 max event time 的增加而增加的,而不是固定的一个时间点。
也就是说,watermark = max event time - late threshold。如下图,spark 关于 watermark 的展示图,spark中watermark的使用参考
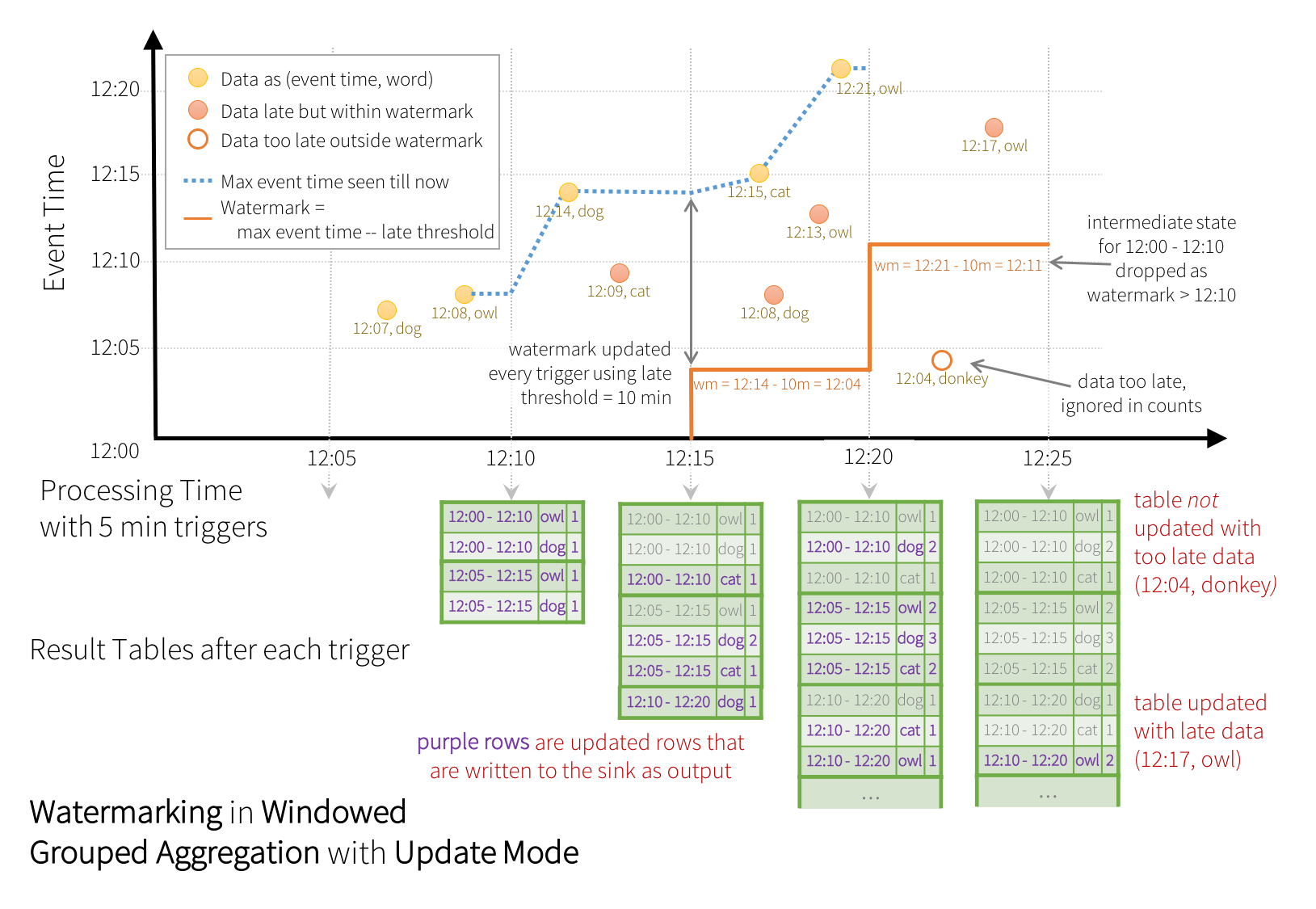
Late events
上面 windowing watermark 可以有效避免 missing events,但是,决定 extra waiting time 并不容易,正常情况下,我们可以估算出 event time 和 processing time 之间的 gap 作为 extra waiting time。
但是,分布式系统中,network delay/data source slow temporarily 都会发生,因此,这个 extra waiting time 需要具体考量。
同时,对于这些 events,它们对应的 window already-closed,我们称为 late events。后续,流系统会 继续处理 或 drop 这些 events。
Join operations
Join operator 在 RDBMS 中是一个比较常见的操作,一个事实表去 join 一个维度表,获取维度的信息。比如,通过 order.city_id 去 join dim_city 获取 city_name。
而在流系统中,join 的双方是 两个 stream,而不是 RDBMS 中的两个不变的表。join 双方的 events 会不断地进入系统,同时这两方的 events 也不可能是实时同步开始处理的(processing time),那如何将不同步的 events 关联起来呢?
回答这个问题前,先看下书中示例,方便解释:
在 event joiner operator 中,需要将 vehicle event source 和 temperature event source 做 join,通过 vehicle_event.zone 去关联 temperature_event.zone,取得 temperature_event.temperature,最终 merge 成新的 event。
重新 recap 这个问题:如何对 constantly moving and updated data 进行 join?
关键点是 将一段时间内的 temperature events 转换为一个 table(mutable memory table),这个 table 会随着新的 events 持续地进行 更新(add / update)。而 vehicle event 则会从 temperature table 中取得对应的 temperature,最终 merge 成新的 event。
Data integrity
inner join 和 outer join 的语义在,streaming join 的内也同样适用。即,如果 vehicle_event.zone 没有关联到 temperature_event.zone,而采用什么的逻辑去 handle 数据完整性。
流系统 与 RDBMS join 的区别,大多数情况下,join 的一边 stream 是 one by one 处理的,而另一边 stream 是 materialized into tables。
Windowed joins
继续 vehicle 和 temperature 的例子。某一天,temperature data source 每隔几个小时才上报一次数据,而不是正常的10min。这导致最终 join 出的 event 的 temperature 可能不是最新的。
当然,你可以通过修复 data source 来解决这个问题,但对一个流系统框架来说,必须考虑到 event source 的 unreliable 问题。
因此,引入了 windowed joins,与上面介绍的 window computation 相似,需要在 join 时引入 windows 概念。即:
temperature 的 materialized view 基于 a fixed window,而不再是持续地根据 events 来更新 table。比如,每隔30min将 buffer 的 events materialized into tables。
但仔细一想,如果 zone 3 没有在一个 window 内上报成功数据,那么 lookup 这个 materialized view 时候,就查不到对应的数据了,虽然比查到老数据让人 confused 好一点。但是,查不到的时候有个 workaround,通过与 zone 3 真实相邻的 zone 2 的 temperature 来替代,这样仍然能够保证数据的及时性。
总结一下思路:通过 window-based materialization 来替代 continuous materialization,虽然提高了一点 temperature change 的 latency(10min to 30min),但是带来了整理系统的 健壮性。
最后,你可能有个疑问,为什么 stream join 的双方不全部作为 mmaterialized tables 后再进行 join?这样就和关系数据库 join 很类似了,我们只需要关注 join logic 即可。但有个流系统至关重要的要求不能满足:latency,物化必然带来了一些延迟,更像小量的批处理,而不是真正的流式持续处理。
Backpressure
backpressure(反压):它是一种错误处理机制,广泛用于分布式系统中,防止系统 breaking down。
讨论 backpressure 之前需要了解如下概念:
- Capacity:一个 instance 能够处理的 最大 events 数量
- Capacity utilization:实际处理的 events number / capacity。值越大,代表更高的资源利用率
- Capacity headroom:utilization 的相反值,代表 instance 还能处理的 extra events number。值越大,代表更大的 resilient 来应对意外,同时也代表较低的资源利用率
一个 resilient 系统的设计,需要能够自己处理一些 temporary issue,而不用人工干预,因此,充足的 headroom 也是系统 resilient 的前提,代表有能力处理。而如果一个 instance 的 utilization 达到 100%,则它不能继续处理 incoming traffic,也就是说 incoming queue 中会不断堆积 events,最终 out of memory。这一处的 issue 最终会 propagate 到其它 components,最终整个系统就会 crash。
利用 backpressure 机制:downstream instance 给 upstream instance 的压力,来 slow down incoming traffic。具体到如何实现,我们简单理解成 OperatorExecutor 减缓 pull queue 的速度,同时利用 blocking queue capacity 特性来控制 insertion rate。
但是,downstream instance backpressure 会不断向上影响。比如,一个 stream fan-in 的 operator 触发的 backpressure,它会导致它上游的所有 operator 处理都会减慢。
尤其在分布式系统中,instance 分布在不同的机器,如何 slow down 并不简单。相比而言,直接 stopping source or upstream components 会更加直接高效。
- stopping sources:直接 temporarily stop data source,让所有 downstream components 缓解压力,尤其是存在多个 busy instances
- stopping upstream components:更加细粒度的控制方式。只会 stop busy instance 的直属 upstream components
注意:backpressure 只是一种 被动的(passive) 处理机制,来缓解整个系统出现雪崩的影响,它并不能让 busy instance 处理更快。因此,如果当前 busy instances 无法恢复,backpressure 可能会多次 trigger。
同时,触发(detect) 和 减轻(relieve) backpressure 的阈值,需要引入 Backpressure watermarks:intermediate queue 的 high / low utilization threshold。由这两个阈值,来决定 declare 或 relieve backpressure。
Stateful computation
对于 long running streaming system 来说,如何保证 软件升级/系统重启/机器迁移 等情况下,系统的 state 仍然保持重启前的状态呢?
关键在于,stateful component 将自身的 checkpoint 持久化到 外部存储,当重启后,再从把数据加载到内存中,来恢复到重启前的状态。
不同组件需要持久化的数据不一样,比如,对于 transaction source 需要 track 当前处理到的位置,即读取 data source 的 offset。对于 usage operator 则不需要持久化状态,因此它是 stateless component。
State
回顾一下 state 定义:state is the internal data inside each instance that changes when events are processed.
拿上面的 transaction source component 举例,它的 state 就是当前读取到的 offset,并且 offset 随着读取的数据不断 增加。
我们知道,对一个 event 来说,在系统中的不同 components,它的 processing time 都是不同的。因此,不同 component 的 state change time 也是不相同的。
Checkpoint
流系统中,有个两个组件负责着 checkpoint 和 state:instance executor 和 checkpoint manager
- save state 流程:instance-executor getState() from instance -> send to checkpoint manager -> checkpoint manager saveState()
- restore state 流程:instance-executor loadState() from checkpoint manager -> restore instance state
上面的两个流程都是 周期性的执行,但仔细发现 checkpoint creation 时间点如何确定,是个棘手的问题,面临如下问题:
如果所有 instance executor 执行 at exactly same time,整体系统就像打了 snapshot 一样处在一个时刻点。然而,在流系统中,events 的 processing time 在不同的 executor instance 上是不同的,
比如,当一个 checkpoint 创建时,eventA 在 source 和 operatorA 内已经处理,但 downstream 的 operatorB 还未来得及处理,因此,如果用此时的 checkpoint 去重建 state,eventA 不会被 source reply,同时 componentB 也会被再处理 eventA 了,从而系统的整体状态 out of sync。
解决方式也很直接:dump all instances’ states at same event-based time,也就是说,在一个 transaction 完全处理完后再进行 checkpoint。
Event-based timing
补充上面提到的 same event-based time:用当前 component 处理的 event id 来代表处理到的 events 位置。
原文如下:For checkpointing in streaming systems, time is measured by event id instead of clock time.
那如何具体实现呢?尤其是在分布式系统环境中,需要实现 parallelization,每个 component 包含多个 instance,不同 instance 处理不同的 events。
基于 wall-clock 的 event-timing 方式,很 straightforward,假设不考虑 clock skew,只要让所有 instance 在同一时刻 create checkpoint 就可以了。
但是基于 event-id-timing,如何让 parallel instances,对外暴露的是一个 compoent,同时也能各自 create checkpoint。需要引入一个 control events。
相比 data events,control events 包含的不是 processing data,而是所有 components 互相通信的 data。
比如 checkpoint 流程:
- checkpoint manager 会周期性地 发出 checkpoint event (包含 event id) 给 source component
- source component 接受到这个 event 后,触发 checkpoint 流程,从 executor 获取 state 交给 checkpoint manager,保存成功后,继续将 checkpoint event 插入到 ongoing stream 中,传递到下游 component 继续相同操作
- 直到 job 中的 最后一个 component 执行完 checkpoint 后,checkpoint manager 才认为这个 checkpoint 完成,并持久化到外部存储中,类似于一个 transaction commit。
上面提到的 parallelization 中,还遗留一个问题 待讨论:multiple-instances checkpoint
问题来源是,parallelization 中提到的 EventDispatcher,它接收不同 executor 的 event,并分发 event 到下游对应的 instance 处理。
但是,当接收到 checkpoint event 不同步时候,EventDispatcher 会 block 先收到 checkpoint event 的 stream,直到收到所有其它 executor 的 checkpoint event,再向下游所有的 instance executor 分发 checkpoint event。
如下图中,event 201 将会被 block 住。从这个角度看,checkpoint event 类似一个 barrier 的作用,来强制让下游所有 instance executors 的 checkpoint 创建时机 在一个 event-id-timing 时刻。

stateful vs stateless components
以上介绍了 stateful components 和 checkpoints,也对应了采用 stateful components 存在的cost,下面从 high-level 比较两种 components:
Accuracy:
- Stateful Component:Stateful computation is important for the
exactly-once semantic, which guarantees accuracy (effectively). - Stateless Component:There is
no accuracy guaranteebecause instance states are not managed by the framework.
Latency (when errors happen):
- Stateful Component:Instances will
roll back to the previous stateafter errors happen. - Stateless Component:Instances will
keep workingon the new events after errors happen.
Resource usage:
- Stateful Component:More resources are needed to manage instance states.
- Stateless Component:No resource is needed to manage instance states.
Maintenance burden:
- Stateful Component:There are more processes (e.g., checkpoint manager, checkpoint storage) to main tain and backward compatibility is critical.
- Stateless Component:There is no extra maintenance burden.
Throughput:
- Stateful Component:Throughput could drop if checkpoint management is not well tuned.
- Stateless Component:There is no overhead to handle high throughput.
Code:
- Stateful Component:Instance state management is needed.
- Stateless Component:There is no extra logic.
Dependency:
- Stateful Component:Checkpoint storage is needed.
- Stateless Component:There is no external dependency.
总结,只有必要时再使用 stateful component,以减少 maintenance 负担。
总结
本书可作为流系统入门材料,浅显且全面地介绍了各种基本概念,帮助读者建立起流系统的知识框架。而涉及到某一块具体的 技术实现,可以参考 Spark Streaming 和 Flink 实现,来帮助补充知识图谱。
同时,强烈推荐 Streaming System 作为后续阅读。